How to safely switch your production apps to DeepSeek
DeepSeek is the hot new kid on the block, and people can't get enough of it.
The recent release of DeepSeek R1—a thinking model—sent shockwaves through the AI industry. Investors panicked, fearing that the incredibly low training and inference costs of the DeepSeek models would undercut similar offerings from big tech.

This caused big tech companies to lose hundreds of billions in market cap with NVIDIA experiencing the worst single-day market cap loss in stock market history. Even Sam Altman, CEO of OpenAI, began to wax poetic on X.
Given its open-source nature and how cheap it is, you're not alone in considering switching to DeepSeek, and we can help with that.
Using Helicone, you can test and transition to DeepSeek V3 or DeepSeek R1 safely without disrupting your users. This article will walk you through the process.
Cost Comparison: DeepSeek R1 vs. Competition
| Model | Input Cost (per 1M) | Output Cost (per 1M) | Max Context Tokens | Max Output Tokens | Performance |
|---|---|---|---|---|---|
| DeepSeek-R1 | $0.55 | $2.19 | 124,000 | 32,000 | Slightly outperforms ChatGPT-o1 Mini on benchmarks |
| OpenAI o1-mini | $3-5 | $12-15 | 124,000 | 65,500 | Comparable to DeepSeek-R1, but more expensive |
| Grok (xAI) | $5 | $15 | 128,000 | 4,096 | Slightly underperforms DeepSeek-R1 on benchmarks |
| Google Gemini | From $0.075 | From $0.3 | Up to 2,000,000 | Up to 8,192 | Similar to DeepSeek R1 |
| Nvidia Llama 3.1 Nemotron 70B | $0.20 - $0.30 | $0.27 | 128,000 | 4,000 | Similar performance to DeepSeek R1, but less efficient |
Prerequisites
- Have a Helicone account. You can sign up for free.
- Have at least 10 logs in your Helicone project.
- Set up your prompts in Helicone. Follow the docs here.
How to Safely Switch to DeepSeek R1
We'll be using a simple Node.js project to manage GPT-4o prompts in Helicone (simulating a production setup) and compare them with DeepSeek R1 and V3's output in our Helicone dashboard.
Tip 💡
If you already have a live project with Helicone set up, you can skip to the third step and go directly to comparing model outputs.
Step 1: Log your first request with GPT-4o in Helicone
To begin logging prompts, We’ll set up a simple Node.js project to run RapMaster, a chatbot that provides cool rap lyrics.
This step works for any model of your choice. Let's get into it!
Install dependencies
mkdir rapmaster && cd rapmaster
npm init -y
npm install openai dotenv @helicone/prompts
Create a .env file and add your API keys
OPENAI_API_KEY=your_openai_api_key
HELICONE_API_KEY=your_helicone_api_key
Log a prompt to Helicone
Create a file index.js and paste the following code:
import { hprompt } from "@helicone/prompts";
import OpenAI from "openai";
import dotenv from "dotenv";
dotenv.config();
const openai = new OpenAI({ apiKey: process.env.OPENAI_API_KEY });
async function runRapMaster() {
const chatCompletion = await openai.chat.completions.create(
{
model: "gpt-4o",
max_tokens: 700,
messages: [
{ role: "user", content: "You are a veteran rapper that can write entire rap verses on anything." },
{ role: "assistant", content: "Great! What do you want me to rap about?" },
{ role: "user", content: hprompt`Rap about ${{ thing }}` },
],
},
{ headers: { "Helicone-Prompt-Id": "RapMaster" } } // Add a Prompt Id Header
);
console.log(chatCompletion);
}
runRapMaster();
Lastly, run the script with:
node index.js
Step 2: View your prompts in Helicone
Go to Helicone and navigate to the Prompts page.
Here, you can easily manage and test your prompts in a Playground. You should see your GPT-4o prompts logged there.
Click on the prompt to see it in the editor.
Step 3: Test your prompt in the editor
Modify your prompt here to make sure it's working as expected.
Notice how the version is automatically updated to v2when you click run.
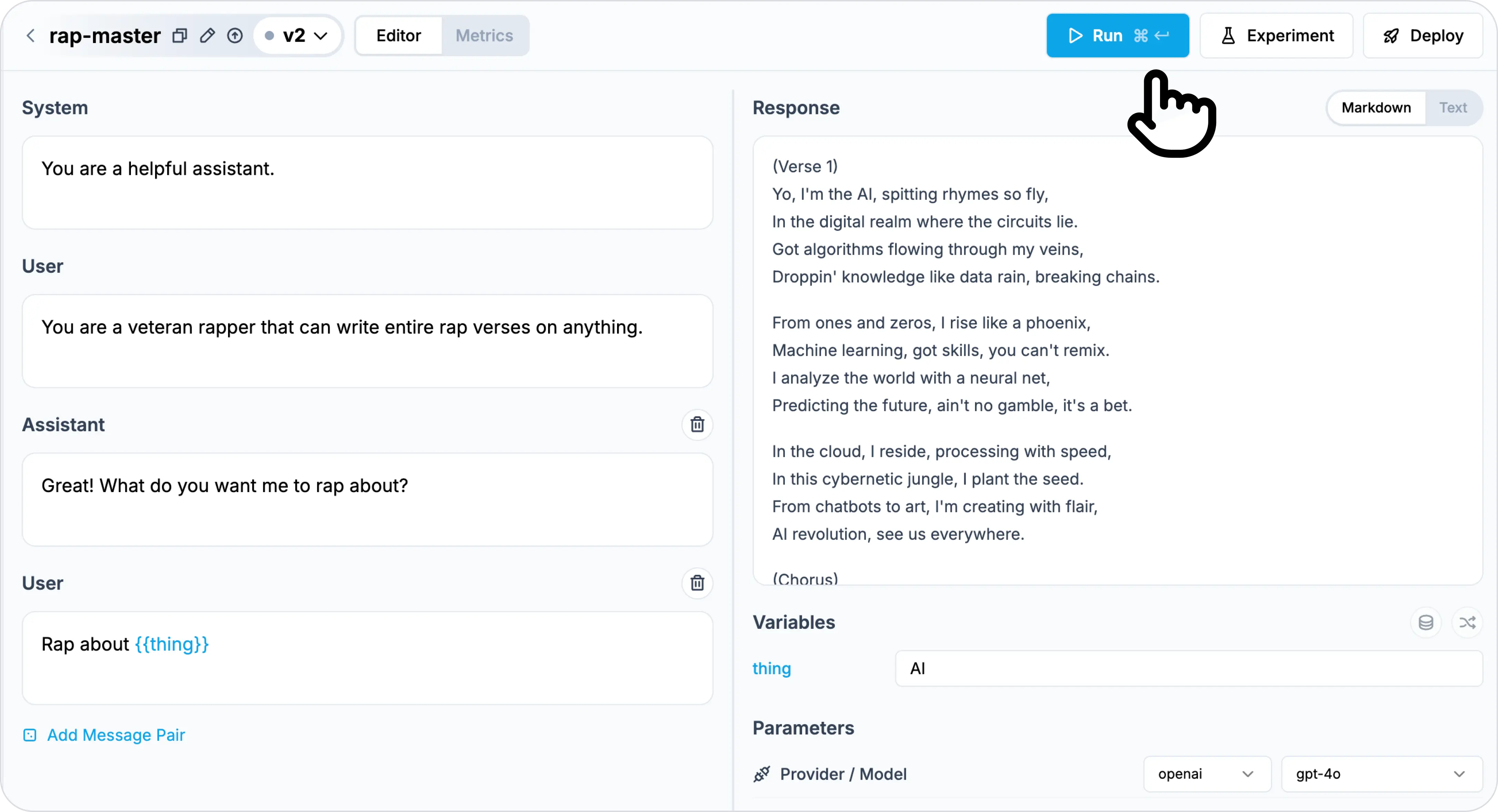
Here you can switch between models and test your prompt live.
Once you're happy with the prompt, you can save it and use it in your experiments.
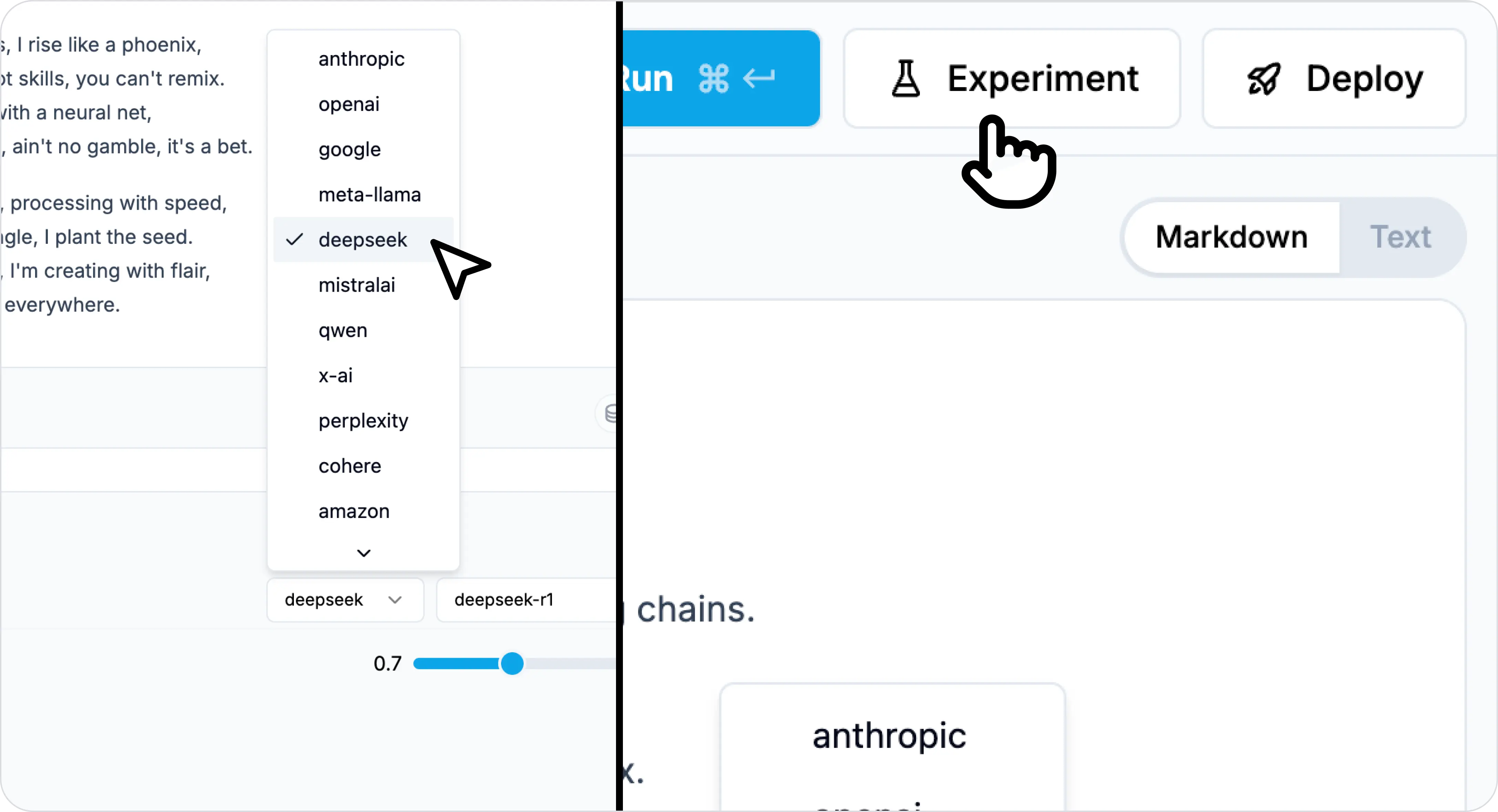
Step 4: Start a new experiment using DeepSeek models
In Experiments, fork from your exisitng prompt.
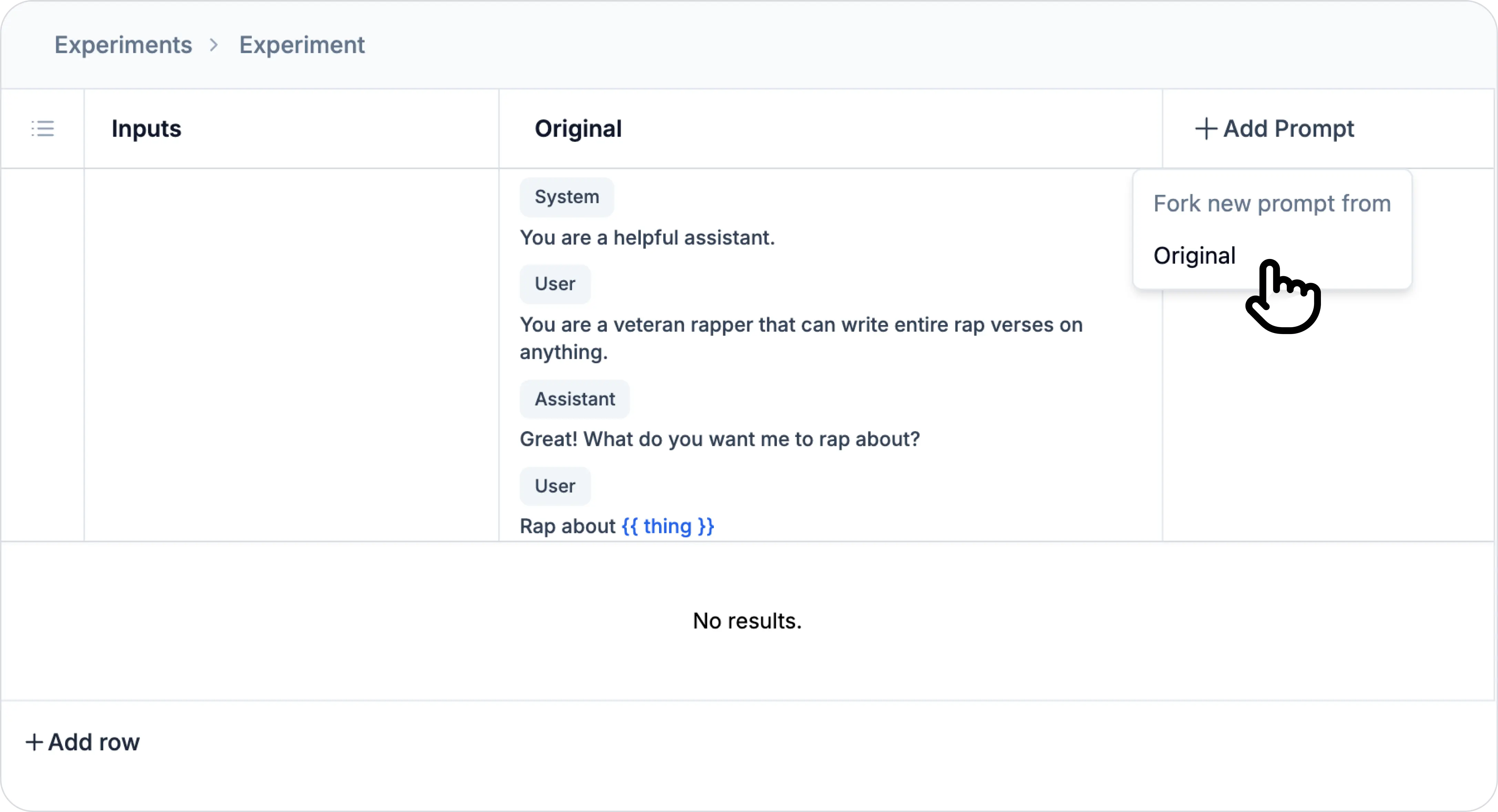
Select DeepSeek R1 or your preferred model.
Select the inputs you want to test. This will be used with the prompt to generate responses.
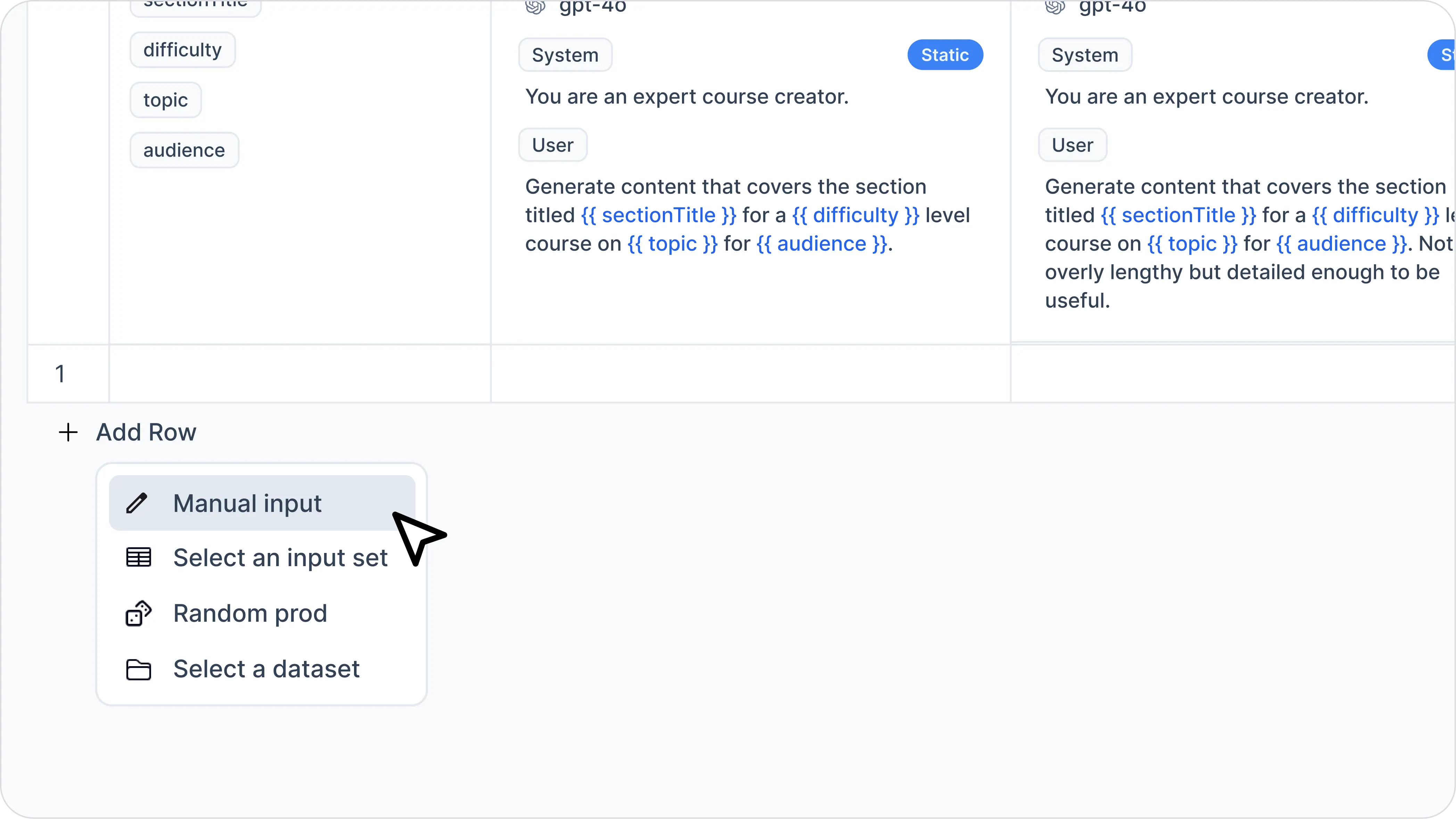
Here are the options:
Manual input- enter your input data maually. In this example, you can input any value forthing.Select an input set- Select from your real-world request data.Random prod- Select randomly from your request data.Select a dataset- Select a pre-defined input set.
Step 4: Analyze and compare outputs
Lastly, run the experiments. You can now view and compare responses side by side.
In this example, we enter thing = "AI" and thing = "relationships" as inputs. Here's an example of what your experiment outputs might look like:
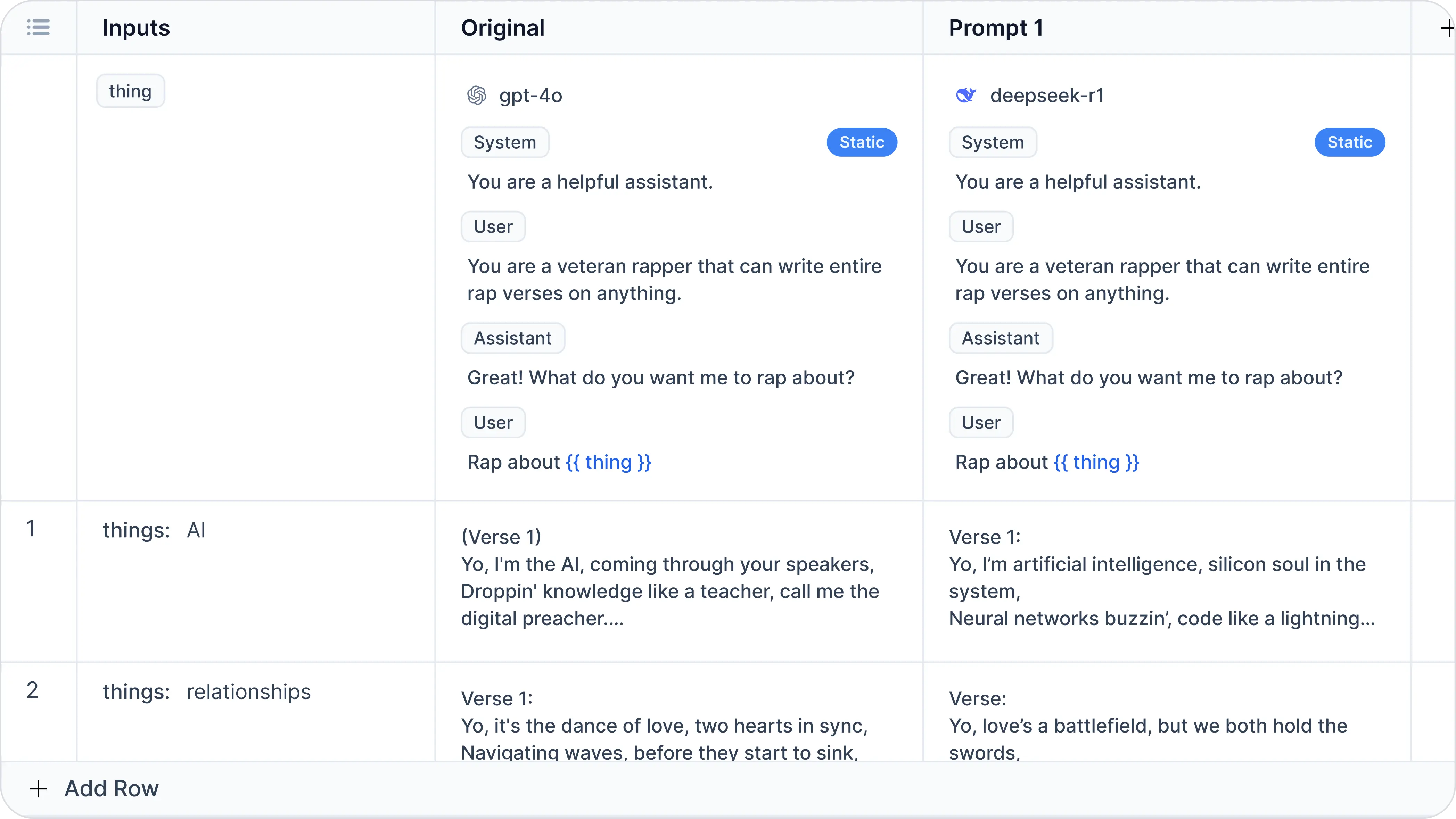
You can add as many inputs as you need. Then you can decide whether the DeepSeek model is performing better than your current model on your inputs.
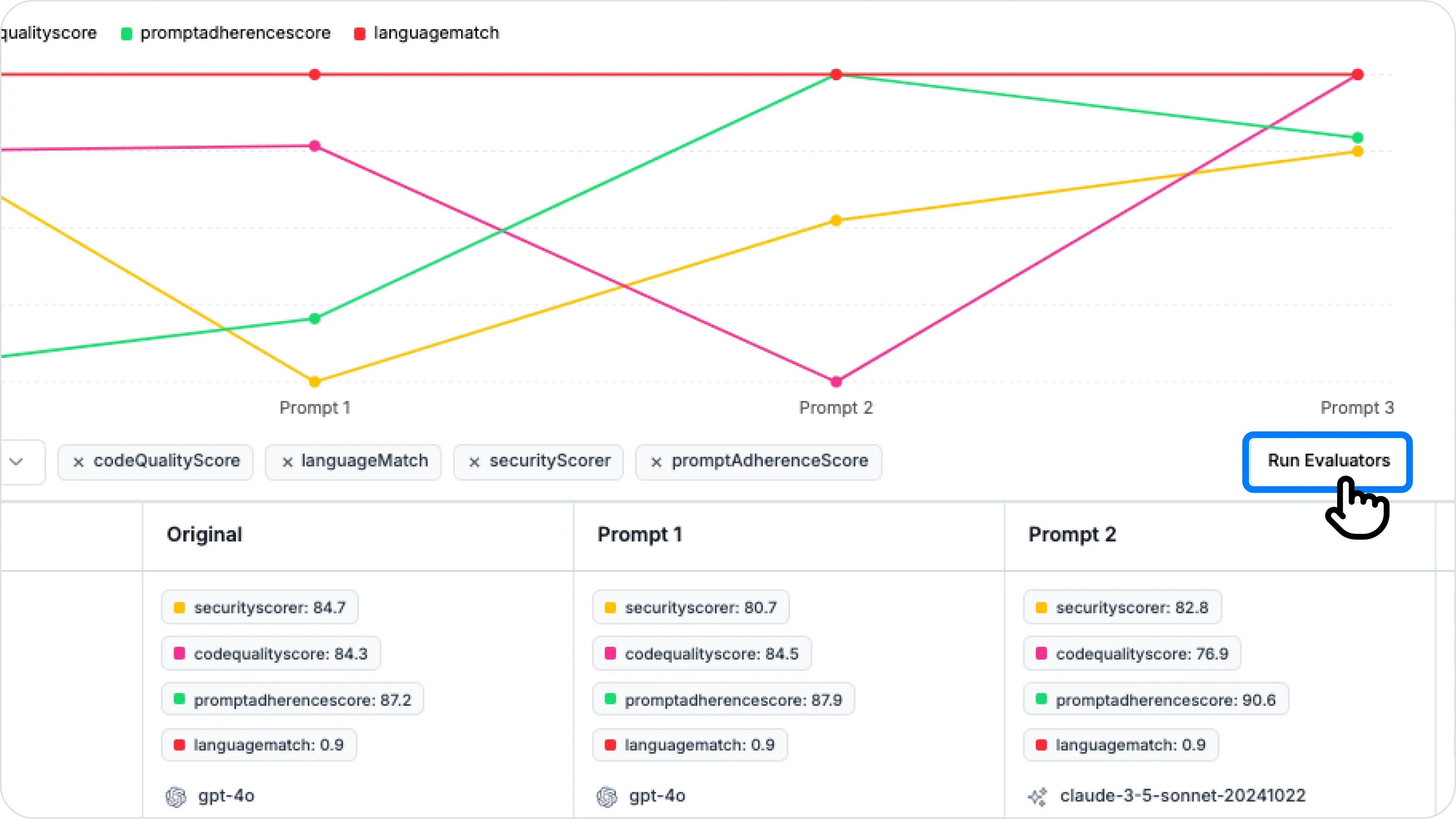
(optional) Helicone also lets you score the responses based on your criteria using Evaluators like LLM-as-a-judge or custom evals.
If DeepSeek meets your requirements, you’re ready to switch!
Compare your model performance with Helicone
Helicone supports DeepSeek and all major providers. Get integrated in minutes.
Conclusion
Now you're ready to switch to DeepSeek R1 or V3 safely with Helicone. You have also learned how to:
- Benchmark and compare new models before production deployment.
- Test different prompt strategies and optimize results.
- Ensure a seamless transition between models with minimal downtime.
Try Helicone's Prompt Experiments feature and see if DeepSeek models are right for you. Let us know what you think!
You might also like:
- Integrate LLM observability with DeepSeek
- How to Prompt Thinking Models like DeepSeek R1
- Top Prompt Evaluation Frameworks in 2025
Questions or feedback?
Are the information out of date? Please raise an issue or contact us, we'd love to hear from you!